Use-case: Video Action Recognition
This document describes a common use-case using Vision Transformer: Video Action Recognition, or Activity Recognition.
Part 1: The Landscape of Video Action Recognition
What is Video Action Recognition?
At its core, video action recognition (or activity recognition) is the task of teaching a machine to identify and classify human actions in a video. It’s not just about identifying objects in each frame, but about understanding the temporal dynamics—the story that unfolds over time.
For an image, the task is “What is in this picture?” (e.g., a person, a ball, a field). For a video, the task is “What is happening in this video?” (e.g., a person is kicking a ball into a goal).
Why is it Important?
It’s a cornerstone technology for many real-world applications:
- Public Safety & Smart Surveillance: Automatically detecting falls, fights, or suspicious activities.
- Sports Analytics: Classifying player actions like “shooting a basketball,” “swinging a golf club,” or “scoring a goal” to generate automated highlights and performance metrics.
- Human-Computer Interaction: Using gestures to control devices or applications.
- Autonomous Vehicles: Understanding the actions of pedestrians and other vehicles (e.g., “person is about to cross the street”).
- Content-based Video Retrieval: Searching for videos based on their content, like “find all videos of people baking a cake.”
The Evolution of Models: From CNNs to Transformers
The key challenge in video is effectively combining spatial information (what’s in a frame) with temporal information (how things change between frames).
-
2D CNN + RNNs: The early deep learning approach was intuitive. Use a pre-trained 2D CNN (like ResNet) to extract features from each frame independently, and then feed this sequence of features into a Recurrent Neural Network (like an LSTM or GRU) to model the temporal relationships.
- Limitation: This separates the learning of space and time, which can be suboptimal. The CNN has no motion awareness.
-
3D CNNs (C3D, I3D): This was a major leap. Instead of 2D convolutions (kernel slides over width and height), these models use 3D convolutions, where the kernel slides over width, height, and time. This allows the model to learn spatio-temporal features (like motion patterns) directly from raw video pixels. The most famous model here is the Inflated 3D ConvNet (I3D), which “inflated” successful 2D CNN architectures (like InceptionV1) into 3D.
- Limitation: Computationally very expensive and memory-intensive due to the 3D convolutions. They also have a limited “temporal receptive field.”
-
The Transformer Revolution: Transformers, which took NLP by storm with their “attention mechanism,” proved to be a natural fit for video. A video can be seen as a sequence of frames or patches, much like a sentence is a sequence of words. Transformers can model long-range dependencies across this sequence, making them excellent for capturing complex, long-form actions.
Part 2: Deep Dive into a Key Model - VideoMAE
Let’s focus on a highly influential and powerful transformer model: VideoMAE (Video Masked Autoencoders). It represents a significant shift in how we train large video models.
The Core Idea of VideoMAE
Imagine you have a jigsaw puzzle. You hide 90% of the pieces and try to figure out what the final picture is just by looking at the remaining 10%. This is incredibly hard, but if you can do it, you must have a deep understanding of how puzzle pieces (shapes, colors, patterns) fit together.
VideoMAE does exactly this with videos. It applies a self-supervised learning strategy where the main goal is not to classify an action, but simply to reconstruct a video from a tiny, random fraction of its content.
How It Works: The Architecture
VideoMAE has two main phases: pre-training (the self-supervised puzzle-solving) and fine-tuning (the actual action classification).
Let’s break down the pre-training architecture:
-
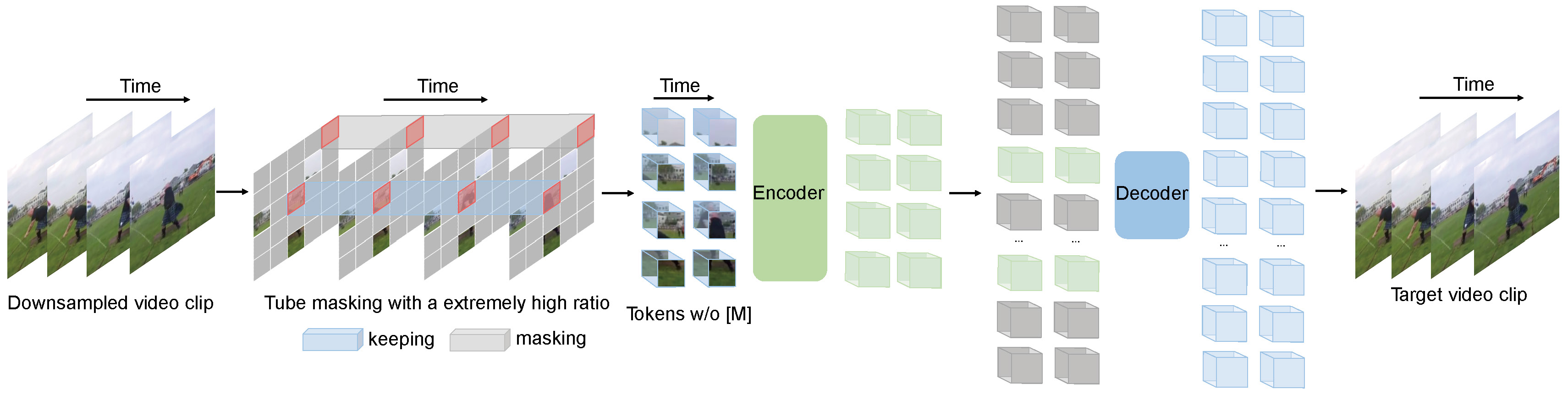
Video to Patches (Tubelets): A video clip is a sequence of frames. VideoMAE divides the video into a grid of non-overlapping 3D “tubelets.” Think of a standard Vision Transformer (ViT) dividing an image into 2D patches; this is the 3D equivalent. Each tubelet is a small block of pixels spanning space (height, width) and time (a few frames).
-
Extreme Masking: This is the magic. The model randomly masks out (hides) a very high percentage of these tubelets—typically 90% to 95%! This seems crazy, but videos have immense temporal redundancy (consecutive frames are often very similar), so the model can leverage this.
-
The Encoder: A standard Transformer encoder (like the one from ViT) is given only the visible tubelets (the remaining 5-10%). Because it processes so few inputs, the encoder is incredibly fast and memory-efficient during pre-training. It processes these visible tubelets and outputs a set of feature-rich representations.
-
The Decoder: Now, the full sequence is reconstructed. The encoded representations of the visible tubelets are put back in their original positions, and special shared
[MASK]tokens are inserted for all the missing tubelets. This complete sequence is fed into a lightweight Transformer decoder. -
The Goal (Reconstruction): The decoder’s job is to use the context from the visible patches to predict the original pixel values of all the masked-out tubelets. The model’s performance is measured by how close its reconstruction is to the original (e.g., using Mean Squared Error).
Why is VideoMAE so Good?
-
Incredibly Data-Efficient (Self-Supervised): The biggest bottleneck in deep learning is the need for massive, human-labeled datasets. VideoMAE’s pre-training is self-supervised, meaning it learns from unlabeled videos. You can feed it terabytes of raw video from anywhere without needing to pay anyone to label “playing basketball” a million times. This allows it to learn rich, general-purpose visual representations.
-
Computationally Efficient Pre-training: By only feeding 5-10% of the video tubelets to the heavy encoder, it drastically reduces the computational load and training time compared to a 3D CNN or a standard transformer that processes the whole video.
-
Learns Meaningful Representations: To reconstruct a masked part of a video (e.g., a person’s moving leg), the model can’t just copy nearby pixels. It must learn a higher-level understanding of both appearance (what a leg looks like) and motion (how a leg moves when kicking). This forces it to learn the semantics of the visual world.
How It Is Trained
-
Pre-training Phase (Self-Supervised):
- Dataset: A massive, unlabeled video dataset (e.g., Kinetics-710, Something-Something V2, or even a custom dataset of unlabeled videos).
- Task: Reconstruct the masked tubelets.
- Loss Function: Mean Squared Error (MSE) between the predicted pixels and the original pixels.
- Result: A powerful encoder that understands video. The decoder is thrown away after this phase.
-
Fine-tuning Phase (Supervised):
- Dataset: A smaller, labeled dataset for the specific task (e.g., Kinetics-400 for general action classification, UCF101, or your own custom action dataset).
- Process:
- Take the pre-trained VideoMAE encoder.
- Remove the decoder.
- Attach a simple classification head (e.g., a single linear layer) to the output.
- Task: Classify the action in the video.
- Loss Function: Standard Cross-Entropy Loss for classification.
- Result: A specialized, high-performance action recognition model.
How to Use a Pre-trained VideoMAE Model
Thanks to the Hugging Face transformers library, using a pre-trained VideoMAE is straightforward. Let’s classify a sample video.
Step 1: Install Libraries and Set Up
pip install transformers torch torchvision torchaudio
pip install "iopath" "av" # For video reading
Step 2: Python Code for Inference
This example uses a model fine-tuned on the Kinetics-400 dataset.
import torch
import av
import numpy as np
from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
# Helper function to read video frames
def read_video_pyav(container, indices):
frames = []
container.seek(0)
for i, frame in enumerate(container.decode(video=0)):
if i in indices:
frames.append(frame.to_ndarray(format="rgb24"))
return np.stack(frames)
# A sample video URL (replace with your video file path if needed)
video_path = "http://images.cocodataset.org/val2017/000000039769.jpg" # This is an image, let's find a video
# Let's use a standard test video from hugging face space
from huggingface_hub import hf_hub_download
np.random.seed(0)
video_path = hf_hub_download(
repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
)
# Load the pre-trained processor and model
processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
# Open the video file
container = av.open(video_path)
num_frames = model.config.num_frames # The model expects 16 frames
# Sample 16 frames evenly from the video
indices = np.linspace(0, container.streams.video[0].frames - 1, num_frames, dtype=int)
frames = read_video_pyav(container, indices)
# Process the video and prepare for the model
# The processor handles normalization, resizing, etc.
inputs = processor(list(frames), return_tensors="pt")
# Perform inference
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# Get the predicted class ID
predicted_class_idx = logits.argmax(-1).item()
# Map the ID to the human-readable class name
predicted_label = model.config.id2label[predicted_class_idx]
print(f"Predicted action: {predicted_label}")
# Expected output for this video: 'eating spaghetti'
Summary
You’ve now seen the whole pipeline:
- The Problem: Understanding actions in videos, which requires modeling space and time.
- The Evolution: From 2D+RNNs to 3D CNNs, leading to Transformers.
- A State-of-the-Art Model (VideoMAE): It uses a clever self-supervised “puzzle-solving” task (masked autoencoding) to learn powerful video representations from unlabeled data efficiently.
- Practical Use: We can easily load a pre-trained and fine-tuned VideoMAE from Hugging Face to classify actions in our own videos with just a few lines of code.
The field is moving incredibly fast, but understanding a foundational and efficient model like VideoMAE gives you a fantastic starting point for exploring more advanced architectures. This is a great time to jump in! Let me know what you’d like to explore next.